线程安全性学习
线程安全性
定义:当多个线程访问某个类时,不管运行时环境采用何种调度方式或者这些进程将如何交替执行,并且在主调代码中不需要任何额外的同步或协调,这个类都能表现出正确的行为,那么就称这个类是线程安全的.
主要体现在 3 个方面
1.原子性:提供了互斥访问,同一时刻只能有一个线程来对它进行操作
2.可见性:一个线程对主内存的修改可以及时的被其他线程观察到
3.有序性:一个线程观察其他线程中的指令执行顺序,由于指令重排序的存在,该观察结果一般杂乱无序.
原子性 - Atomic 包
AtomicXXX: CAS(Unsafe.compareAndSwapInt()实现,原理:只有当工作内存的值和主内存的值是一致的时候,才会执行对应操作,否则不会执行)
AtomicInteger
1 | public static int clientTotal = 5000;// 请求总数 |
AtomicXXX 相关的类:
AtomicLong,LongAdder(jdk1.8 新增,可理解为 AtomicLong 的优化版)
AtomicLong
1 | public static int clientTotal = 5000;// 请求总数 |
LongAdder
1 | public static int clientTotal = 5000;// 请求总数 |
为什么要引入 LongAdder?
AtomicLong 是利用了底层的 CAS 操作来提供并发性的,比如 addAndGet 方法源码如下:
1 | public final long addAndGet(long delta) { |
上述方法调用了 Unsafe 类的 getAndAddLong 方法,该方法是个 native 方法,它的逻辑是采用自旋的方式不断更新目标值,直到更新成功。在并发量较低的环境下,线程冲突的概率比较小,自旋的次数不会很多。但是,高并发环境下,N 个线程同时进行自旋操作,会出现大量失败并不断自旋的情况,此时 AtomicLong 的自旋会成为瓶颈。
这就是 LongAdder 引入的初衷——解决高并发环境下 AtomicLong 的自旋瓶颈问题
LongAdder 快在哪里?
既然说到 LongAdder 可以显著提升高并发环境下的性能,那么它是如何做到的?这里先简单的说下 LongAdder 的思路,第二部分会详述 LongAdder 的原理。
我们知道,AtomicLong 中有个内部变量 value 保存着实际的 long 值,所有的操作都是针对该变量进行。也就是说,高并发环境下,value 变量其实是一个热点,也就是 N 个线程竞争一个热点。
LongAdder 的基本思路就是分散热点,将 value 值分散到一个数组中,不同线程会命中到数组的不同槽中,各个线程只对自己槽中的那个值进行 CAS 操作,这样热点就被分散了,冲突的概率就小很多。如果要获取真正的 long 值,只要将各个槽中的变量值累加返回。
这种做法有没有似曾相识的感觉?没错,ConcurrentHashMap 中的“分段锁”其实就是类似的思路。
LongAdder 原理
AtomicLong 是多个线程针对单个热点值 value 进行原子操作。而 LongAdder 是每个线程拥有自己的槽,各个线程一般只对自己槽中的那个值进行 CAS 操作。
比如有三个 ThreadA、ThreadB、ThreadC,每个线程对 value 增加 10。
对于 AtomicLong,最终结果的计算始终是下面这个形式: value=10+10+10=30
但是对于 LongAdder 来说,内部有一个 base 变量,一个 Cell[]数组;
base 变量:非竞态条件下,直接累加到该变量上;
Cell[]数组:竞态条件下,累加个各个线程自己的槽 Cell[i]中
最终结果的计算是下面这个形式:value=base+(Cell 数组从下标 0 到 n 的和)
LongAdder 只有一个空构造器,其本身也没有什么特殊的地方,所有复杂的逻辑都在它的父类 Striped64 中.大致原理如下:
将AtomicLong的内部核心数据value分离成一个数组,每个线程访问时,通过哈希等算法映射到其中一个数字进行计数,而最终的计数结果,则为这个数组的求和累加。热点数据value被分离成多个单元cell,每个cell独自维护内部的值,当前对象的实际值由所有的cell累计合成,这样热点就进行了有效的分离,提高了并行度。
LongAdder设计的精妙之处:尽量减少热点冲突,不到最后万不得已,尽量将CAS操作延迟。
AtomicReference,AtomicReferenceFieldUpdater
AtomicReference
1 | private static AtomicReference<Integer> count = new AtomicReference<>(0); |
AtomicReferenceFieldUpdater(Class)
1 | private static AtomicIntegerFieldUpdater<AtomicDemo> updater = |
AtomicStampReference:CAS 的 ABA 问题
ABA 问题描述:
例如有 2 个线程同时对同一个值(初始值为 A)进行 CAS 操作,这三个线程如下,线程 1,期望值为 A,欲更新的值为 B;线程 2,期望值为 A,欲更新的值为 B;线程 1 抢先获得 CPU 时间片,而线程 2 因为其他原因阻塞了,线程 1 取值与期望的 A 值比较,发现相等然后将值更新为 B,然后这个时候出现了线程 3,期望值为 B,欲更新的值为 A,线程 3 取值与期望的值 B 比较,发现相等则将值更新为 A,此时线程 2 从阻塞中恢复,并且获得了 CPU 时间片,这时候线程 2 取值与期望的值 A 比较,发现相等则将值更新为 B,虽然线程 2 也完成了操作,但是线程 2 并不知道值已经经过了 A->B->A 的变化过程
比如:在提款机,提取了 50 元,因为提款机问题,有两个线程,同时把余额从 100 变为 50
线程 1(提款机):获取当前值 100,期望更新为 50,
线程 2(提款机):获取当前值 100,期望更新为 50,
线程 1 成功执行,线程 2 某种原因 block 了,这时,某人给小明汇款 50
线程 3(默认):获取当前值 50,期望更新为 100,
这时候线程 3 成功执行,余额变为 100,
线程 2 从 Block 中恢复,获取到的也是 100,compare 之后,继续更新余额为 50!!!
此时可以看到,实际余额应该为 100(100-50+50),但是实际上变为了 50(100-50+50-50)这就是 ABA 问题带来的成功提交。
解决方法: 在变量前面加上版本号,每次变量更新的时候变量的版本号都+1,即 A->B->A 就变成了 1A->2B->3A
原子性 - 锁
synchronized: 依赖 JVM,子类继承 synchronized 的方法的时候,子类是不含 synchronized 的,必须手动声明 synchronized
修饰代码块: 修饰范围是大括号括起来的代码,作用于调用的对象,不同对象之间不影响
1 | // 修饰一个代码块 |
修饰方法:修饰范围是整个方法,作用于调用的对象,不同对象之间不影响
1 | // 修饰一个方法 |
修饰静态方法:修饰范围是整个静态方法,作用于所有对象
1 | // 修饰一个类 |
修饰类:修饰范围是 class 括起来的部分,作用于所有对象
1 | // 修饰一个静态方法 |
Lock:依赖特殊的 CPU 指令,代码实现,ReentrantLock
1 | Lock lock; |
原子性对比:
synchronized:不可中断锁,适合竞争不激烈,可读性好,JVM 自动释放锁
Lock:可中断锁,多样化同步,竞争激烈时能维持常态,必须手工释放锁
可见性
导致共享变量在线程间不可见的原因可能有:
1.线程交叉执行
2.重排序结合线程交叉执行
3.共享变量更新后的值没有在工作内存与主内存间及时更新
synchronized,具有可见性和原子性
JMM 关于 synchronized 的两条规定:
1.线程解锁钱,必须把共享变量的最新值刷新到主内存
2.线程加锁时,将清空工作内存中共享变量的值,从而使用共享变量时需要从主内存中重新读取最新的值(注意:加锁与解锁是同一把锁)
volatile,不具有原子性
通过加入内存屏障和禁止重排序优化来实现
对 volatile 变量写操作时,会在写操作后加入一条 store 屏障指令,将本地内存中的共享变量值刷新到主内存中去
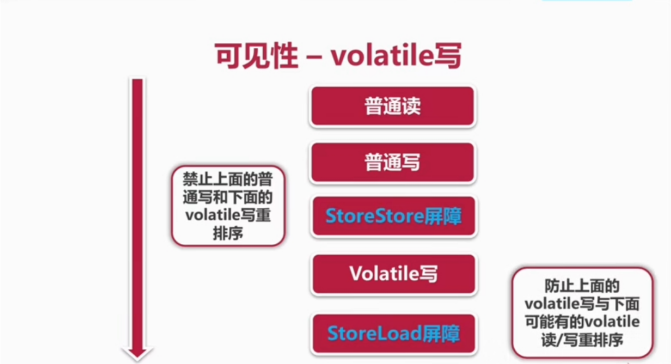
对 volatile 变量读操作时,会在读操作前加入一条 load 屏障指令,从主内存中读取共享比变量

使用 volatile 必须依赖的原则:1.对变量的写操作不依赖当前值;2 该变量没有包含具有其他变量的不必要的式子中.
volatile 适用的场景:1.作为状态标记量;2.double check(双重检查)
有序性
在 JMM 中,允许编译器和处理器对指令进行重排序,但是重排序过程不会影响到单线程的执行,却会影响到多线程并发执行的正确性
Java 中,volatile,synchronized,lock 都能保持有序性
有序性的八条原则(happens-before 原则):
1.程序次序原则:单个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作
2.锁定规则:一个 unlock 操作先行发生于后面对同一个锁的 lock 操作
3.volatile 变量原则:对一个变量的写操作先行发生于后面对这个变量的读操作
4.传递原则:如果操作 A 先行发生于操作 B,而操作 B 又先行发生于操作 C,则可以得出操作 A 先行发生于操作 C
5.线程启动规则:Thread 对象 的 start()方法先行发生于此线程的每一个动作
6.线程中断原则:对线程的 interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生
7.线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过 Thread.join()方法结束,Thread.isAlive()的返回值手段检测到线程已经终止运行
8.对象终结规则:一个对象的初始化完成先行发生于他的 finalize()方法的开始