数据库设计概念
数据库设计就是根据业务系统的具体需要,结合自身选择的DBMS(数据库管理系统),为该业务系统设计出最优的数据存储模型.建立好数据库中表与表之间的关系过程,使之能对业务系统中的数据进行存储和高效访问.
逻辑设计
将业务系统的需求转化为数据库的逻辑模型,通过ER图的方式对逻辑模型进行展示.
第一范式(1NF)
数据库表中的所有字段都是不可再分的单一属性,这个单一数据一般用基本的数据类型构成.比如,整形,浮点,字符串等.换句话说,第一范式的要求是数据库中所有的数据表都是二维表
数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。如果出现重复的属性,就可能需要定义一个新的实体,新的实体由重复的属性构成,新实体与原实体之间为一对多关系。在第一范式(1NF)中表的每一行只包含一个实例的信息。简而言之,第一范式就是无重复的列。
第二范式(2NF)
第二范式是在第一范式的基础之上建立的,数据库的表中不存在非关键字端对任意候选关键字段的部分 函数依赖(存在组合关键字中的某一关键字觉得非关键字的情况).
第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。例如员工信息表中加上了员工编号(emp_id)列,因为每个员工的员工编号是惟一的,因此每个员工可以被惟一区分。这个惟一属性列被称为主关键字或主键、主码。
第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。简而言之,第二范式就是属性完全依赖于主键。
第三范式(3NF)
第三范式是在第二范式的基础之上定义的,如果表中不存在非关键字段对任意候选关键字段的传递函数依赖则符合第三范式.
第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主关键字信息.例如,存在一个部门信息表,其中每个部门有部门编号(dept_id)、部门名称、部门简介等信息。那么在的员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。如果不存在部门信息表,则根据第三范式(3NF)也应该构建它,否则就会有大量的数据冗余。简而言之,第三范式就是属性不依赖于其它非主属性。 也就是说, 如果存在非主属性对于码的传递函数依赖,则不符合3NF的要求
BC范式
BC(Boyce.Codd)范式是在第三范式的基础之上,数据库表中如果不存在任何字段对任一候选关键字段的传递函数依赖则符合BC范式.也就是说如果是复合关键字,则复合关键字之间也不能存在函数依赖关系.
物理设计
选择合适的数据库管理系统,定义数据库/表/字段的命名规范,根据所选的数据库管理系统选择合适的字段类型,反范式设计
选择合适的数据库管理系统
通常情况下,商业化应用大多采用Oracle,SQL Server,互联网应用及小型企业应用通常采用开源的MySQL和pgsql(另外也会跟所使用的编程语言有关,比如.net通常采用SQL Server;PHP和Java则通常采用MySQL等)
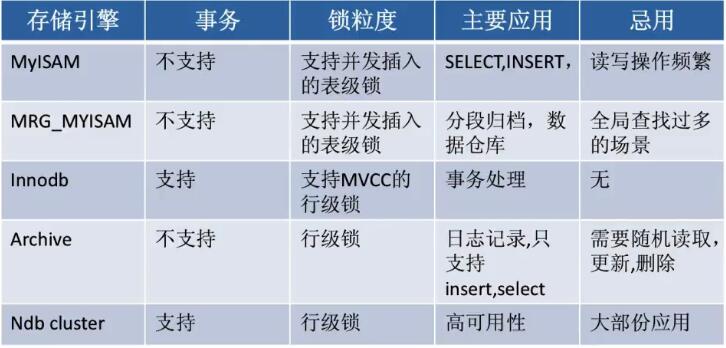
选择合适的存储引擎(MySQL为例)
表和字段的命名规则
1.可读性原则.使用大写和小写来格式化库对象名字以获取良好的可读性.(注:不同的数据库系统可能对大小写敏感区分的)
2.表意性原则.对象的名字应该能够描述它所表示的对象.比如:表的名称应该能够体现出表中存储的数据内容;存储过程的名称则应该体现出其具体的功能
3.长名原则.尽可能少使用或者不使用缩写
表字段类型的选择原则
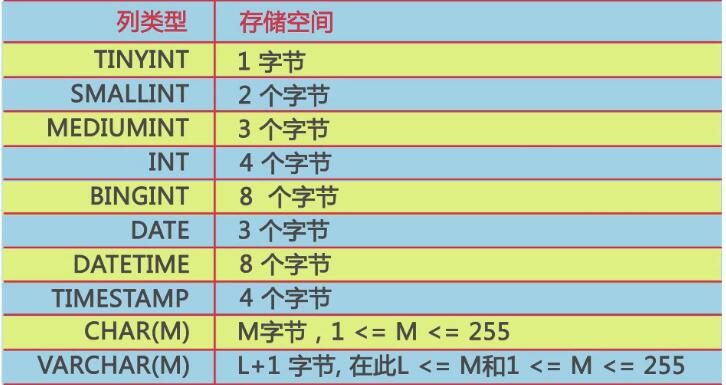
列的数据类型一方面影响数据存储空间的开销,也会影响数据的查询性能.当一个列可以选择多种数据类型时,应该优先考虑数字类型,其次是日期或者二进制类型,最后是字符串类型.对于相同级别的数据类型,应该优先选择占用空间小的数据类型.
MySQL的数据类型和对应的存储空间如图:
一般的选择原则从2个角度考虑:
1.在对数据进行比较(查询条件,JOIN条件及排序)操作时,同样的数据,字符处理往往比数字处理慢
2.在数据库中,数据处理以页为单位,列的长度越小,利于性能提升
3.char和varchar的选择:
3.1 如果列中要存储的数据长度差不多一致,优先考虑char,否则varchar
3.2 如果列中的最大数据长度小于50Byte,一般考虑char(如果该列很少用,则基于节省空间和I/O的考虑,也可以选择varchar)
3.3 一般不定义大于50Byte的char类型列
4.decimal和float的选择:
4.1 decimal用于存储精度数据,float只能用于存储非精度数据.
4.2 由于float的存储空间开销一般比decimal小,所以非精度数据优先选择float类型
5.时间类型存储选择
5.1 使用int存储.(优点:字段长度比datetime小.缺点:使用不方便,需要用函数进行转换.限制:只能存储到2038-01-19 11:04:07即2^32=2147483648的值)
5.2 需要存储的时间粒度(年月日时分秒)
6.主键的选择
6.1 区分业务主键和数据库主键.业务主键用于标示业务数据,进行表之间的关联;数据库主键为了优化数据存储(innodb会生成6个字节的隐含主键)
6.2 根据数据库类型,考虑主键是否需要自增长(有些数据库是按主键的逻辑顺序存储的)
6.3 主键的字段类型所占的空间要尽可能的小
7.避免使用外键约束
7.1 使用外键会降低数据导入的效率,增加维护成本
7.2 虽然不建议使用外键,但是相关联的列上一定要建立索引
8.避免使用触发器
8.1 使用触发器会降低数据导入的效率
8.2 使用触发器可能会出现数据异常
8.3 使用触发器使业务变得更复杂
9.严禁使用预留字段
10.反范式化设计
反范式化是针对范式化而言的,有时候为了性能和读取效率的提升,要考虑适当的对第三范式进行违反,允许少量的数据冗余,使用空间来换取时间.
反范式化优点和注意
1. 减少表的关联数量
2. 增加数据的读取效率
3. 反范式化要适度使用,不能过度使用
数据库维护(如:MySQL)
维护数据字典
使用第三方工具进行或者在建表的时候使用注释字段,然后再进行导出数据字典
维护索引
选择合适的列建立索引,原则如下
1. 出现在WHERE从句,GROUP BY从句,ORDER BY从句的列
2. 可选择性高的列要放在索引的前面
3. 索引中不要包括太长的数据类型
维护索引
1. 索引不是越多越好,过多的索引会降低读写效率
2. 定期维护索引碎片
3. 在SQL语句中不要使用强制索引关键字
维护表结构
1.使用线性变更表结构工具(MySQL5.5版本之前可采用pt-online-schema-change工具,5.6版本之后本身支持在线表结构更改)
2.同时要对数据字典进行维护
3.要控制表的宽度和大小
4.数据库中通常适合的操作如下
4.1 批量操作和逐条操作
4.2 禁止使用select *
4.3 控制使用用户自定义函数
4.4 不要使用数据库中的全文索引(使用专业的全文检索工具,如ES)
5.表的拆分
1.为了控制表的宽度(字段的数量),可以进行表的垂直拆分,垂直拆分原则
1.1.经常查询用到的列要放在一起
1.2.text ,blob等大字段要拆分到附加表中
2.为了控制表的大小(行数),可以进行表的水平拆分,水平拆分主要对主键的控制.例如下图: